
Cluster Analysis
Cluster analysis foundations rely on one of the most fundamental, simple and very often unnoticed ways (or methods) of understanding and learning, which is grouping “objects” into “similar” groups. This process includes a number of different algorithms and methods to make clusters of a similar kind. It is also a part of data management in statistical analysis.
When we try to group a set of objects that have similar kind of characteristics, attributes these groups are called clusters. The process is called clustering. It is a very difficult task to get to know the properties of every individual object instead, it would be easy to group those similar objects and have a common structure of properties that the group follows.
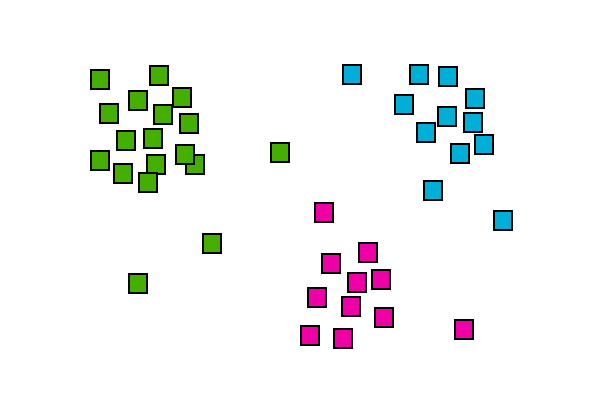
What is Cluster Analysis?
Cluster analysis is a multivariate data mining technique whose goal is to groups objects (eg., products, respondents, or other entities) based on a set of user selected characteristics or attributes. It is the basic and most important step of data mining and a common technique for statistical data analysis, and it is used in many fields such as data compression, machine learning, pattern recognition, information retrieval etc.
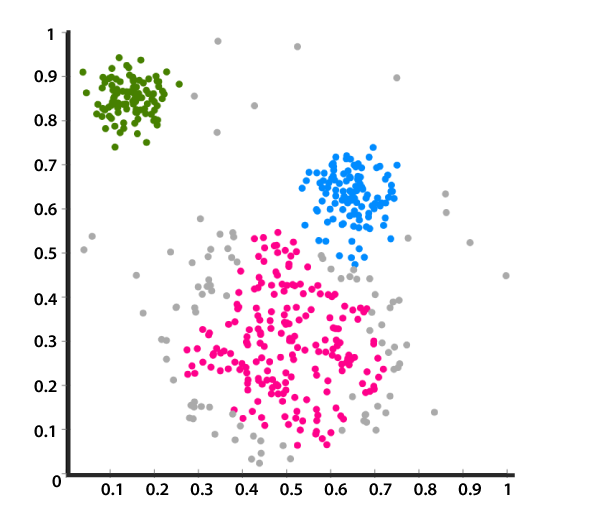
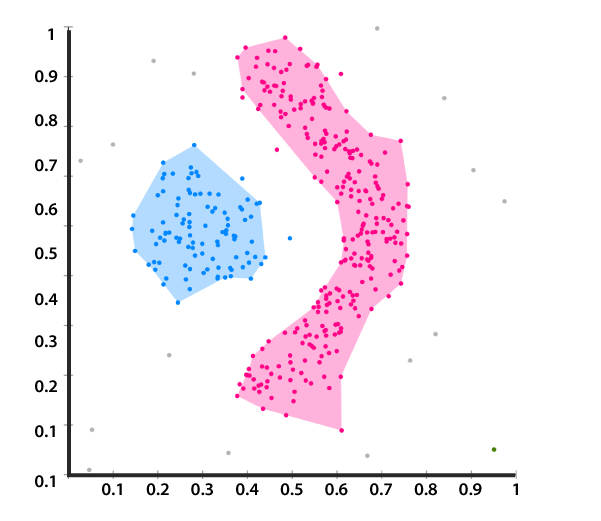
Clusters should exhibit high internal homogeneity and high external heterogeneity.
What does this mean?
When plotted geometrically, objects within clusters should be very close together and clusters will be far apart.
Related Articles:
Types of Cluster Analysis
The clustering algorithm needs to be chosen experimentally unless there is a mathematical reason to choose one cluster method over another.It should be noted that an algorithm that works on a particular set of data will not work on another set of data. There are a number of different methods to perform cluster analysis. Some of them are,
Hierarchical Cluster Analysis
In this method, first, a cluster is made and then added to another cluster (the most similar and closest one) to form one single cluster. This process is repeated until all subjects are in one cluster. This particular method is known as Agglomerative method. Agglomerative clustering starts with single objects and starts grouping them into clusters.
The divisive method is another kind of Hierarchical method in which clustering starts with the complete data set and then starts dividing into partitions.
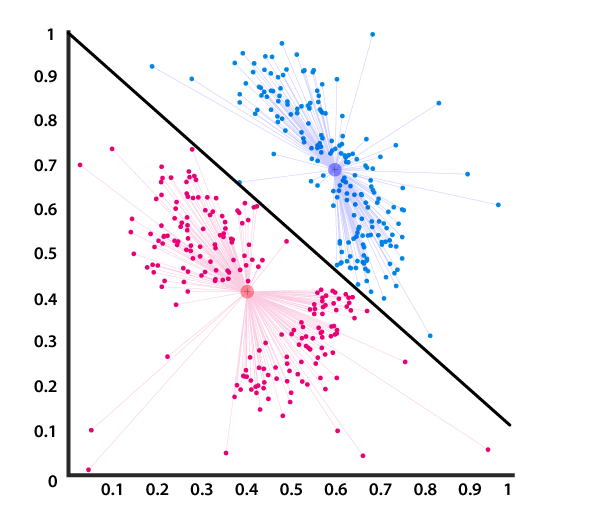
Centroid-based Clustering
In this type of clustering, clusters are represented by a central entity, which may or may not be a part of the given data set. K-Means method of clustering is used in this method, where k are the cluster centers and objects are assigned to the nearest cluster centres.
Distribution-based Clustering
It is a type of clustering model closely related to statistics based on the modals of distribution. Objects that belong to the same distribution are put into a single cluster.This type of clustering can capture some complex properties of objects like correlation and dependence between attributes.
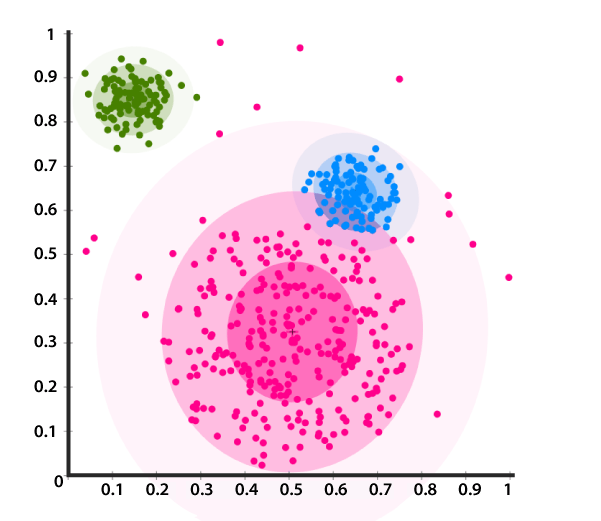
Density-based Clustering
In this type of clustering, clusters are defined by the areas of density that are higher than the remaining of the data set. Objects in sparse areas are usually required to separate clusters.The objects in these sparse points are usually noise and border points in the graph.The most popular method in this type of clustering is DBSCAN.
To learn more on the cluster and other statistics-related topics, visit BYJU’S.
Applications and Examples
It is the principal job of exploratory data mining, and a common method for statistical data analysis. It is used in many fields, such as machine learning, image analysis, pattern recognition, information retrieval, data compression, bioinformatics and computer graphics.
It can be used to examine patterns of antibiotic resistance, to incorporate antimicrobial compounds according to their mechanism of activity, to analyse antibiotics according to their antibacterial action.
Cluster analysis can be a compelling data-mining means for any organization that wants to recognise discrete groups of customers, sales transactions, or other kinds of behaviours and things. For example, insurance providing companies use cluster analysis to identify fraudulent claims and banks apply it for credit scoring.